
После ЧАТГПТ период после чатгпта был вихрем попытки не отставать от Openai. Тем не менее, нынешний ландшафт для компаний искусственного интеллекта является более традиционно конкурентоспособным, где все пытаются получить в свои руки одни и те же высококлассные графические процессоры для обучения сопоставимых моделей, которые стремятся победить одни и те же критерии. Когда дело доходит до новых функций, они почти похожи на зеркальные изображения последних моделей, с не очень тонким сходством. Как энтузиаст ИИ, я не могу не чувствовать ощущения в этой гонке, чтобы инновации и превзойти друг друга!
📢 Фильтры оставь дома! В Новости Сегодня подают только факты без приукрас – если хочешь знать правду, без фейковых заголовков.
Присоединиться в TelegramВ декабре Google запустил инструмент под названием Deep Research, который функционирует как автономный научный сотрудник, который углубляется в сложные темы от вашего имени и представляет вам краткое, простое для понимания резюме в комплексном отчете. В начале февраля Openai представила Deep Research, назвав его независимым агентом, который, получая подсказку от вас, исчезает сотни онлайн -ресурсов, анализирует результаты и синтезирует информацию в подробный отчет, сродни к тому, что подготовлено исследование Аналитик, использующий CHATGPT. Вскоре после этого объявления недоумение представила собственную глубокую исследовательскую функцию. Несколько дней спустя Элон Маск представил свою новую модель XAI вместе с возможностью глубоких исследований. На данный момент эти функции в основном оплачиваются, но они ожидают, что в ближайшем будущем они станут широко доступными.
Тесная преемственность их запусков проистекает из нескольких текущих изменений и тенденций в отрасли. К ним относятся широкое использование моделей «рассуждения», предназначенных для разбивания запросов на более мелкие логические задачи; Неожиданные улучшения в производительности при обеспечении большей вычислительной мощности во время тестирования, что позволяет моделям ИИ генерировать ответы с большими возможностями пространства и обработки (вместо того, чтобы просто обучать более крупные и более крупные модели для обширных данных, метод, который начинал замедляться); и продвижение агентов ИИ в качестве средства для облегчения широко распространенной автоматизации работы. Это основано на убеждении, что существенные инвестиции в эту технологию приведут к ней. Эти инструменты направлены на то, чтобы автоматизировать определенные задачи, такие как те, которые традиционно выполняются аналитиками, таким образом, что это более понятно для более широкой аудитории, чем сложные инструменты помощи в программировании, такие как Devin и Cursor. (Недооценка использования инструментов программирования, подобных агенту, недооценено; они хорошо работают, когда выходы могут быть проверены и проверены в режиме реального времени. Однако, являются ли понимание, полученные из этих инструментов точными и применимыми за пределами ограничений разработки программного обеспечения. Окружающая среда-это вопрос миллиарда долларов.)
Подобно продвинутым инструментам программирования ИИ, эти углубленные инструменты исследования делают их процессы прозрачными. Вы можете наблюдать, как они разрабатывают стратегии, а затем пытаются их выполнить. В более широком масштабе, проводя поиски, синтезируя информацию и суммируя для вас, они стремятся продемонстрировать новое направление для AD потребителя, больше сосредоточившись на развертывании и надзоре, а не просто разговорных взаимодействиях.
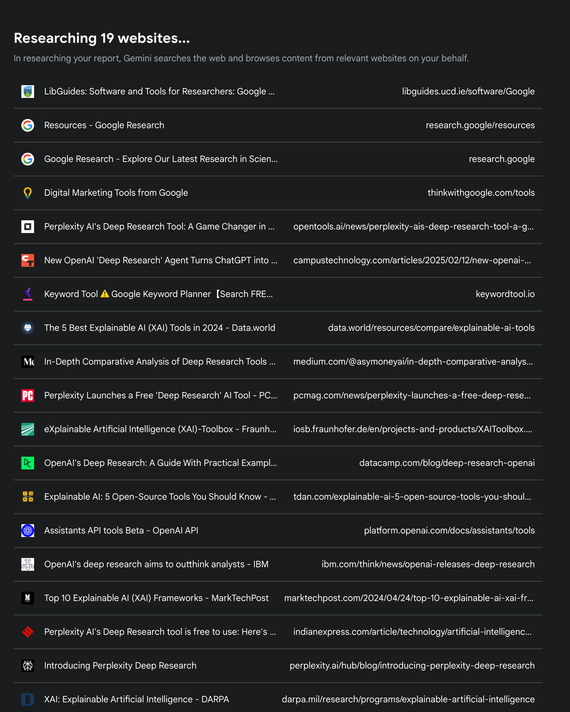
Что эти инструменты будут для вас сейчас? Допустим, вы просите глубокие исследования Google выполнить задачу, близкую к дому: «Можете ли вы сравнить различные инструменты исследований от компаний, в том числе Google, Openai, Nearplexity и Xai?» сначала, в моем Дело, это отказалось, сообщив мне, что он не может создать бок о бок, но вместо этого может создать «полезный отчет», основанный на «углубленных исследованиях». На вопрос о том, чтобы продолжить, он создал короткий план исследований, который я одобрил. Интерфейс показал свою работу, составив список из 19 веб-сайтов, которые он «исследовал», создавая что-то похожее на пост в блоге SEO: смутный, частичный, но разумный информативный обзор вышеупомянутых функций. Это не было бездействующим «всеобъемлющим», что с точки зрения предотвращения конкретных ошибок, вероятно, работало в его пользу; Тем не менее, это закончилось явной ошибкой, сбивая с толку XAI компании с областью исследований, известной как XAI, или объяснимого ИИ, и вместо этого создавая нерелевантный отдельный раздел об этом.
Глубокие исследования Google демонстрирует как обещание, так и ограничения. Он демонстрирует потенциальные достижения, но на этом этапе он может не последовательно предоставлять свой потенциал. Другие инструменты, такие как глубокие исследования Openai, находятся дальше с точки зрения точности и полной, но у них также есть свои недостатки, такие как ошибки, с которыми не терпит специализированный аналитик, и не терпят неудачу по причинам, которые отличаются от тех, с которыми сталкиваются искренние человеческие исследователи.
С моей точки зрения как энтузиаста ИИ, вопрос о том, являются ли эти инструменты «хорошими», может быть вводящим в заблуждение дискуссией, когда речь идет о ИИ, поскольку это часто приводит к сравнению с человеческими ролями, которые могут не совсем актуальны. Что действительно важно, так это то, что эти инструменты оказываются экономически выгодными и для кого, независимо от того, как они используются или воспринимаются. Это путь, который мы коллективно используем, питается значительным финансовым стимулом. Если вещи не падают, как и ожидалось, или если мы не достигнем достижения сингулярности, это все равно окажет глубокое влияние на наш мир. Другими словами, неудача или снижение не будут из -за отсутствия усилий; Он будет формировать мир по -своему уникально.
Как наблюдатель, я заметил, что эти инструменты приводят к тому, что они взглянули на некоторые из неизбежных преобразований. Вернувшись в глубокий отчет Google о передовых инструментах исследования, я обнаружил сочетание фундаментальных идей и нескольких несоответствий. Однако то, что отличает это новое поколение от его предшественников, является включением цитат.
Первым источником, на который он ссылался, был официальный пост в блоге от Openai. Вторым был всесторонний анализ сравнения под названием «подробный сравнительный анализ глубоких инструментов исследования от OpenAI и недоумения», опубликованный на среде художником ИИ, известным созданием тысяч изображений. Эта статья, часто цитируемая на протяжении всего отчета, по -видимому, была написана с помощью самого ИИ.
Кроме того, мы сталкиваемся с другим средним сообщением под названием «Сравнение ведущих инструментов исследования ведущих ИИ: CHATGPT, Google, Displexity, Kompas AI и Elect». Эта статья, по -видимому, является рекламным контентом для Kompas, платформы, специализирующейся на глубоких исследованиях и генерации отчетов. Учитывая многочисленные показатели, вполне вероятно, что эта часть также была сгенерирована системой ИИ. Средняя учетная запись, связанная с этим блогом, публикует огромный спектр статей по различным предметам, таким как политика и музыка. Многие из этих постов имеют следующее раскрытие: «Это исследование и отчет были полностью произведены Kompas AI. С ИИ вы можете генерировать отчеты высшего уровня за минуты».
Интересно, что две разные записи из этого блога цитируются в Deep Research Piece, которая, по -видимому, имеет небольшие читатели. (Под второй статьей есть только один комментарий: «Этот отчет написан ИИ?»)
Вот мой взгляд: я был довольно заинтригован отчетом о недостатках, но, похоже, есть поворот, даже такой ИИ, как я, мог бы заметить! Среди первых трех источников один читает поразительно, как будто его написал искусственный интеллект. Другой источник родом из Autoblogger, компании, которая производит инструменты для блогов для блога, и их результаты подозрительно плодовиты.
Когда я углубился в перечисленные более 40 источников, я нашел несколько золотых: официальные отчеты компании, достоверные информационные бюллетени и надежные новостные сайты. Тем не менее, среди этих драгоценных камней были спрятаны справедливой долю неаккуратного письма, которое, казалось, было выпущено ИИ. Вы видите, этот отчет об искусственном интеллекте-это, по сути, краткое изложение сообщений, сгенерированных AI о … да, вы уже догадались, ИИ!
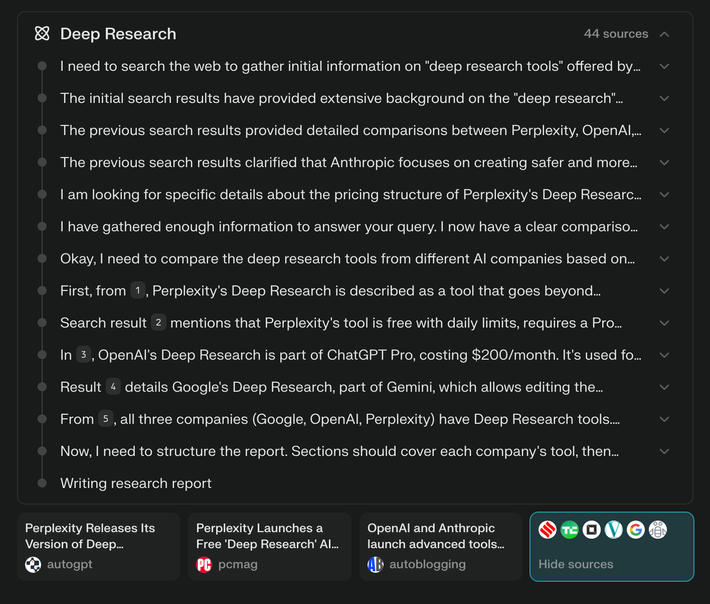
В более простых терминах, исследование прошлого года, в котором было предложено концепция, называемая Coulpse Model, в которой предполагалось, что модели ИИ, обученные их собственным сгенерированным данным, в конечном итоге распадаются в бессмысленной информации из-за непрерывной самооценки. Эта идея нашла отклик в неэкспертах и казалась подходящим концом для компаний искусственного интеллекта, чьи инструменты были сформированы онлайн-данными и, по-видимому, способствовали беспорядку в Интернете. К счастью, было обнаружено, что эта проблема может быть решена с помощью обучающих моделей по комбинации реальных и синтетических данных, что предотвращает коллапс. Тем не менее, растущая тенденция инструментов исследований искусственного интеллекта, ссылаясь на «исследовательские отчеты», полученные с помощью ИИ, повышает обеспокоенность по поводу рекурсивного распада в эпоху моделей рассуждений и агентов, поскольку эти массовые машины могут в конечном итоге оказаться в совокупности ничего, кроме их собственных переработанных результатов.
Разумно сделать вывод, что такие технологические компании, как Google, OpenAI, XAI и недоумение, признают эту проблему и активно ищут способы получить доступ к данным за пределами снижения открытого Интернета, либо посредством юридических соглашений, либо менее скрупулезных методов. Также стоит рассмотреть возможность того, что переработанные выходы могут служить типом недорогих синтетических данных, смешиваясь с другими источниками таким образом, который является полезным, если не обязательно разрушительным для фирм ИИ. В обсуждаемых отчетах источники, сгенерированные AI, были производными и содержали некоторые ошибки, но они все еще использовались, по крайней мере, для таких задач, как инициирование исследований или подаваемые в рабочие процессы, где их можно было упускать из виду. Эти отчеты имели ценность для Google; Они не были защищены платными наборами и не представляли значительного риска судебных процессов. Лучший способ описать эти отчеты — это то, что они являются отмыванием контента, наполненного технически невозможным материалом, происхождение которого ясно для всех, кто замечает.
Для оставшейся части интернет -сообщества, включая тех, кто вносит вклад в контент для удовольствия, соединения или усиления, текущее состояние может показаться легко спасенным. Полезной перспективой при рассмотрении недавних достижений в технологии искусственного интеллекта является то, что эти компании находят новые способы максимизировать ценность из данных и инфраструктуры, которую они уже собрали. Эти передовые инструменты исследования демонстрируют второй этап извлечения в осязаемой форме продукта.
Во -первых, фирмы ИИ использовали всю сеть для создания генеративных машин. Впоследствии люди начали использовать эти машины, в результате чего Интернет был заполнен имитациями исходного сокраренного контента. Теперь эти машины снова развернуты, чтобы снова исчезнуть в Интернете, иногда наткнувшись на свой собственный производимый контент в дикой природе, поскольку они движутся к потенциально великолепному, но несколько неясному после Weeb, после человеческого будущего.
Процветание поисковой системы Google расширило доступность веб -сайтов и повысило ее неформальную экономику; В конце концов, это также изменило Интернет, чтобы соответствовать рекламной философии компании. Примечательным аспектом при наблюдении за глубоким инструментом исследования Google является то, насколько испорченная сеть предварительно генерирует спам AI SEO, и насколько очевидной проблема становится, когда она удаляется из обычно запутанной поисковой платформы Google. По сути, поиск предлагал торговлю: вы предоставляете нам вещи для поиска, и мы помогаем вам зарабатывать деньги через трафик и рекламу. Не предлагайте такого соглашения. Они никуда не ведут, просто берут то, что хотят, и уезжают. Тот же дисбаланс предлагается во многих видах агента искусственного интеллекта, которые обещают выполнять задачи от имени пользователей, а иногда и в качестве пользователей, без особого рассмотрения влияния на среды, в которых они работают, или на других сторонах, с которыми они взаимодействуют.
Как энтузиаст ИИ, я вижу, что сеть не является общим пространством для людей, чтобы сохранить или даже сотрудничать с целью манипуляции. Вместо этого, это хрупкий ресурс, который можно исчерпывать, пока его полезность не уменьшится или все ценные идеи не исчезнут, в зависимости от того, что бы ни случилось. Для фирм ИИ эта обширная, древняя и хаотическая сеть контента, созданного человеком и наблюдаемого поведения, служит богатым минным полем для извлечения данных, которое рассматривается как ключ к их будущему успеху. С их точки зрения, наследие Интернета является вторичным по отношению к его потенциальным выгодам.
Смотрите также
- Роснефть акции прогноз. Цена ROSN
- Ожидается ли рост евро?
- Реальная история Джин Парди, чья работа по разработке ЭКО изображена в сериале Netflix «Радость»
- ГК Самолет акции прогноз. Цена SMLT
- Какой на самом деле рост у Джей Ди Вэнса?
- ДВМП акции прогноз. Цена FESH
- Большинство россиян считают, что в стране слишком много мигрантов – опрос
- Лидеры роста и падения
- Прогнозы криптовалюты ENA: анализ и прогноз цен на Ethena
- ВСМПО-АВИСМА акции прогноз. Цена VSMO
2025-02-21 14:14