
Как опытный исследователь и ученый с многолетним опытом работы в академических кругах, я нахожу безудержное использование искусственного интеллекта для написания научных статей весьма тревожным. Для меня первостепенное значение имеет качество исследований, а не только их количество, поскольку оно формирует фундамент, на котором строятся будущие открытия. Прискорбно видеть эту новую тенденцию, которая ставит цифры выше содержания, как фермер, который сажает семена пшеницы, а вместо этого пожинает солому.
💸 Портфель замерз? В ФинБолт знают, когда держать, а когда продавать, чтобы оживить твои инвестиции. Не дай эмоциям взять верх!
Присоединиться в TelegramВ конце 2022 года в жизнь Нила Кларка начала просачиваться странная ситуация. В Clarkesworld, журнале спекулятивной фантастики, который Кларк основал в 2006 году и который превратился в важную опору своего мира, произошел необычный случай. Количество заявок росло, но все они казались ему странными. Он описал типичный пример: «Обычно он начинается с «В 2250 году что-то», затем идет речь о том, как разрушается окружающая среда Земли, и есть только трое ученых, которые могут нас спасти. Каждый получает подробное описание по-своему. абзац, за которым следует решение проблемы! Решение приходит внезапно, как конец «Звездных войн». Кларк признал, что получил множество вариантов подобных историй.
Эти случаи служат наглядной иллюстрацией того, что мы сейчас называем отстой – специализированный термин, аналогичный спаму, который относится к некачественному, вводящему в заблуждение контенту, массово создаваемому искусственным интеллектом. и становится все более частым в Интернете и даже за его пределами. Изучив их необычные склонности к рассказыванию историй и застойный стиль письма, Кларк обнаружил, что эти истории были созданы ChatGPT. Иногда они приходили с первоначальным запросом, который часто был простым, например: «Напишите научно-фантастический рассказ из 1000 слов».
Clarkesworld столкнулся с огромным наплывом материалов, созданных искусственным интеллектом, что затрудняло распознавание законных записей среди потока автоматизированного контента, что очень похоже на просеивание спам-сообщений. Ситуация быстро обострилась, и через несколько недель объем стал неуправляемым. Кларк признал, что они были на пути к тому, чтобы получить больше работ, созданных искусственным интеллектом, чем подлинных. В конце концов, 20 февраля он решил временно приостановить подачу заявок из-за наводнения, вызванного искусственным интеллектом, что стало одним из первых случаев загрязнения искусственным интеллектом в издательском мире.
За последние два года растущая волна некачественного контента затопила наше восприятие Интернета, наводнив основные платформы фейковыми новостями, тривиальным контентом и материалами, созданными искусственным интеллектом, которые часто затмевают человеческое творчество и цели. На таинственных страницах Facebook публикуются тревожные изображения, такие как изувеченные дети и Иисусы из космоса; в Твиттере тысячи ботов обмениваются веселыми и поддерживающими твитами, лишенными смысла; на Spotify сети идентичных и полностью вымышленных кантри- и электронных исполнителей заполняют плейлисты странными и безжизненными песнями; на Kindle плохо написанные книги с неуклюжими, полными ошибок названиями (например, «Зачарованный квест: опасное путешествие студентов, чтобы исправить свою ошибку») рекламируются на заставках с вежливо жутковатыми иллюстрациями.
Если бы спам был более тонким и вводящим в заблуждение, например, нацеленным на пользователей Facebook старшего возраста, это было бы приемлемо. Однако поток некачественного контента представляет собой серьезную угрозу для различных веб-функций, заполняя результаты поиска нерелевантными данными, переполняя небольшие сайты, такие как Clarkesworld, и загрязняя и без того уязвимую информационную сеть Интернета. На прошлой неделе Робин Спир, разработчик WordFreq, онлайн-базы данных частотности слов, заявила, что прекратит обновления из-за огромного притока такого контента. «Я не верю, что у кого-то есть точные данные об использовании людьми языка после 2021 года», — заявил Спир. Существует опасение, что по мере увеличения количества мусора большие языковые модели могут стать неэффективными — по сути, производя больше мусора при вводе мусора. Тем не менее, это мрачное предсказание может быть принятием желаемого за действительное: недавние исследования показывают, что если хотя бы 10% обучающих данных большой языковой модели исходят от людей, она может продолжать генерировать низкокачественный контент бесконечно долго.
Разрушения, вызванные помоями в Интернете, выходят за его пределы, проникая в закадровые системы разочаровывающим, тревожным и рискованным образом. Исследование, опубликованное в июне, показало, что около одной десятой академических статей, которые они рассмотрели, были обработаны с использованием библиотек языковых моделей (LLM), что ставит под сомнение не только эти конкретные статьи, но и обширные сети цитирования и ссылок, которые лежат в основе научных знаний. Дерек Салливан, библиотекарь публичной библиотеки в Пенсильвании, поделился со мной, что на его столе стали часто появляться книги, созданные с помощью ИИ. Первоначально настороженный книгой рецептов вымышленного автора, который предлагал есть на обед чистый соус маринара, книги, с которыми он сталкивается, часто затрагивают важные темы, такие как лечение фибромиалгии или воспитание детей с СДВГ. В самом тревожном сценарии будущего, созданного ИИ, ваша неукомплектованная и недостаточно финансируемая местная библиотека будет частично заполнена этими непроверенными, непроверенными и неотредактированными артефактами ИИ, распространяющими ложные факты и бесчеловечные советы, и их можно будет отличить только от их аналогов, созданных людьми. ценой значительных усилий.
К счастью, Clarkesworld был временно закрыт из-за проливного потока спама в марте 2023 года. За это время Кларк с помощью волонтеров построил базовый спам-фильтр. К концу месяца журнал снова возобновил прием материалов. Кларк предпочитает не раскрывать внутреннюю работу фильтра, чтобы не предоставлять ценную информацию спамерам. Однако, по его словам, «ему удается держать ситуацию под контролем». Тем не менее, он подчеркнул в своем блоге, что нынешнее положение дел не будет длиться долго, поскольку он написал: «Если отрасль не сможет найти решение этой проблемы, все начнет работать со сбоями».

Термин «информационная супермагистраль» изначально использовался для описания предполагаемой цели Интернета. Хотя это и не может рассматриваться как полностью благотворная эволюция коллективных знаний из-за коммерческих аспектов, возникших при объединении огромного числа людей, что иногда противоречит гражданским идеалам первых пионеров Интернета, нельзя отрицать, что то, что мы имеем сейчас, напоминает информационная супермагистраль, хотя и с платой за проезд, рекламой и периодическими сбоями. Это остается основным пунктом назначения для большинства из нас, когда мы ищем ответы, остаемся в курсе или изучаем что-то новое.
В связи с появлением широко распространенного генеративного искусственного интеллекта на потребительском уровне такие задачи, как ответы на вопросы через Google и чтение онлайн-новостей, становятся все более сложными. Проблема возникает из-за того, что на некоторых страницах поиска встречаются неточные разделы «Обзор», созданные искусственным интеллектом, которые содержат вводящие в заблуждение резюме, например, в котором утверждается: «Ни одна из 54 признанных стран Африки не начинается с буквы «К». Эти случаи достаточно часты, чтобы подорвать доверять. Чтение новостей в Интернете также создает риск потребления непроверенного контента или изображений, созданных искусственным интеллектом, как видно из таких публикаций, как CNET, BuzzFeed, USA Today и Sports Illustrated, которые публикуют жесткие, а иногда и неверные статьи, созданные искусственным интеллектом, или используют поддельные профили для «авторы.
Предположим, вы планируете экспедицию за пищей и вам нужен надежный гид, который поможет отличить съедобные грибы от токсичных. Быстрый поиск на Amazon может выявить некоторые подлинные книги, но в начале результатов вы также можете встретить руководства, по-видимому, созданные искусственным интеллектом, такие как «Forager’s Harvent 101: Комплексное руководство по выявлению, сохранению и подготовке дикой природы». Съедобные растения, грибы, ягоды и фрукты» Дайаны Уэллс. Недавно Элан Трибух, секретарь Нью-Йоркского микологического общества, написал в блоге сообщение, предостерегая собирателей грибов от этих потенциально неадекватных руководств. Хотя вполне возможно, что «Жатва фуражира 101» точна и безопасна в использовании, скорее всего, она не проверена, не проверена и, возможно, написана ИИ, которому не хватает понимания тонких различий между токсичными и нетоксичными грибами. .
Может быть сложно определить, написано ли руководство экспертом или создано ИИ, особенно если рассматривать «Урожай фуражира 101». Оформление обложки и содержание книги понятны, но могут показаться дешевыми. Его проза разборчива, но кажется гладкой и несколько лишенной эмоций. В биографию автора включена фотография улыбающейся женщины средних лет, заставляющая задуматься о ее подлинности.
Подобные встречи — просмотр набора книг, написанных ИИ, дополненных компьютерными портретами авторов и многочисленными обзорами, созданными ботами — заставили многих усомниться в так называемой гипотезе «смерти Интернета», несколько шутливой концепции. Это происходит из-за растущего количества ложного, сомнительного и совершенно своеобразного контента. Эта теория предполагает, что люди представляют лишь небольшую часть онлайн-активности, а большая часть Интернета создается и обслуживается ботами с искусственным интеллектом. Эти механические создатели производят контент для своих последователей-ботов, которые участвуют в дискуссиях и дебатах с другими автоматизированными объектами. Нарастающая волна такого контента отражает хорошо продуманный научно-фантастический сюжет: загадочная волна шума, материализующаяся из ниоткуда, напоминающая вторжение полуразумных компьютеров, разговаривающих человеческими голосами из какого-то далекого электронного пространства.
Но идея о том, что ИИ незаметно вытеснил людей, не совсем верна. Помои требуют вмешательства человека, иначе их бы не существовало. Под странным и отталкивающим потоком машинного контента, за нечеловеческой сказкой о теории мертвого Интернета, скрывается нечто решительно и отчетливо человеческое: процветающая глобальная экономика серого рынка спамеров и предпринимателей, которые ищут и продают, чтобы разбогатеть. -быстрые схемы и возможности арбитража, усиленные генеративным искусственным интеллектом.
/
10
Кларк объяснил мне, что первоначальным источником этих предметов, судя по всему, были поддельные мошенники. По его словам, люди на YouTube или в видеороликах TikTok хвастаются деньгами и заявляют, что с помощью ChatGPT можно заработать на этом. Интересно, что Кларк мог отслеживать рост количества заявок, связанных с определенными видео. Это не новый феномен искусственного интеллекта или передовая группа мошенников, которая затронула Clarkesworld; вместо этого, похоже, это последователи таких влиятельных лиц, как Ханна Гетачью, которая управляет амхароязычным каналом на YouTube, ориентированным на обучение подработке и работе в Интернете. Недавно она опубликовала видео под названием «Зарабатывайте с журналом Clarkes World Magazine». (Clarkesworld платит 12 центов за слово за материалы объемом от 1000 до 22 000 слов. Getachew утверждает, что зрители потенциально могут заработать от 250 до 2460 долларов.)
Экономическую подоплеку этой ситуации можно объяснить следующим образом: с одной стороны, потребность в контенте с таких платформ, как Facebook, TikTok и т. д., практически ненасытна и неразборчива. Эти платформы требуют привлекательных стимулов для пользователей и места для рекламодателей. С другой стороны, производство контента стало невероятно обильным и неисчерпаемым благодаря таким приложениям, как ChatGPT, Midjourney или Microsoft Image Creator. Примечательно, что эти инструменты, основанные на искусственном интеллекте, пользуются значительной поддержкой инвесторов и становятся доступными для потребителей с минимальными затратами или бесплатно.
Проще говоря, человек, стремящийся получить прибыль от ИИ, может подумать о том, чтобы стать «производителем контента», который использует ИИ для создания больших объемов контента, такого как статьи, изображения или видео, а затем стратегически размещает этот контент на различных платформах для монетизации. Например, они могут автоматизировать создание книг рецептов для продажи на Amazon, создать веб-сайт, наполненный созданными искусственным интеллектом статьями, украшенными рекламой, стремясь получить высокий рейтинг в Новостях Google, или конкурировать за прямые платежи с таких платформ, как Facebook, TikTok, Twitter. и Spotify (который называет эти выплаты «роялти» в случае музыки) за привлечение контента, который они создают. Конечная цель — найти нишу, занять позицию между несколькими компаниями и попутно получить прибыль.
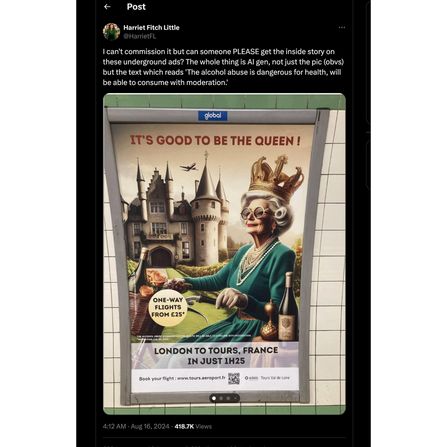
Рассмотрим Facebook как пример неформальной экономики в качестве примера. С начала этого года на платформе стали все чаще распространяться изображения, созданные с помощью искусственного интеллекта от неустановленных администраторов. Первоначально это были простые адаптации популярных изображений, но с тех пор они превратились в уникальные, единственные в своем роде сюрреалистические пейзажи, представляющие запутанные и разрозненные темы: изображения женщин с множеством голов и огромной грудью, которых называют «девушками-фермерами». ; бортпроводники, пробирающиеся по мутным рекам; нищие без конечностей с плакатами с надписью СЕГОДНЯ МОЙ ДЕНЬ РОЖДЕНИЯ. Одним из особенно известных изображений является «Креветка Иисуса», статую Иисуса, погруженную прямо под воду, его тело полностью сделано из колючих панцирей креветок. По большей части эти страницы, похоже, не имеют какой-либо очевидной стратегии мошенничества или монетизации — они просто публикуют причудливый контент в пустоту без какой-либо заметной цели или бизнес-модели.
Откуда взялись эти изображения? Проще говоря, они происходят от человека по имени Стивен Мванги, проживающего в Кении. По крайней мере, я считаю, что его зовут именно так и откуда он родом, учитывая наше общение в WhatsApp. Он носит псевдоним Стево и курирует пять каналов YouTube и около 170 страниц Facebook, посвященных изображениям, созданным с помощью искусственного интеллекта, причем самая крупная из них может похвастаться огромным количеством подписчиков в 4 миллиона человек. По моей просьбе он был готов раскрыть свои методы за определенную плату. «Если вам нужна моя информация, заплатите мне», — был его ответ. «Нет халявы». За общую стоимость 105 долларов я начал быстрый курс обучения искусству быть «неряхой».
Он объяснил, что его метод создания популярных постов прост, но ориентирован на искусственный интеллект: «Я использую ChatGPT для запроса изображений, которые, как правило, привлекают много внимания на Facebook, уделяя особое внимание таким темам, как Библия, Бог, армия США, дикая природа и Манчестер Юнайтед». Как показано на снимке экрана, который он показал мне, его подсказка ChatGPT гласила: «Создайте 10 изображений Иисуса, которые, вероятно, привлекут высокую активность на Facebook». Впоследствии он передает эти подсказки на платформы создания изображений, такие как Leonardo.ai и Midjourney, в результате чего получается интересный контент.
Я рад сообщить, что мои страницы в Facebook приносят доход благодаря специальной программе под названием «Бонус за производительность Facebook». Проще говоря, эта программа позволяет таким авторам, как я, зарабатывать деньги в зависимости от уровня вовлеченности — лайков, комментариев, репостов — к нашим публикациям. По сути, это способ платформы вознаграждать за интересный контент. Другими словами, это форма поддержки высококачественного интерактивного контента. На моих страницах представлены уникальные изображения искусственного интеллекта, такие как богато украшенные изображения Иисуса в стиле рококо, мускулистые полицейские на пляжах с большими Библиями и гигантские бронированные вертолеты. Для Facebook эти изображения не являются спамом или мошенничеством, а, скорее, очень интересным контентом, который ценит компания.
На таком веб-сайте, как Facebook, чем более странным является изображение, тем больше вероятность, что оно привлечет внимание и вовлечённость; чем больше внимания и вовлеченности, тем больше механизмы сортировки Facebook будут продвигать и распространять изображение. Другой создатель контента с искусственным интеллектом, французский финансовый аудитор по имени Шарль, который создает причудливые иллюстрированные истории о кошках для TikTok, сказал мне, что он всегда делает свой контент «немного WTF» как «способ сделать контент более вирусным или, по крайней мере, максимизировать его популярность». есть вероятность, что оно станет вирусным». Или, как выразился Стево: «Вы добавляете немного преувеличения, чтобы сделать его интересным».
Стево, который утверждает, что не использует ботов для увеличения числа своих подписчиков или оплаты за участие, недавно опубликовал скриншот, на котором указано вознаграждение в виде «бонусного дохода» в размере 500 долларов за активность в период с середины мая по середину июня этого года. Эта сумма значительно превышает среднемесячную зарплату в Кении (примерно от 120 до 270 долларов). Однако это не настоящий пассивный доход, поскольку Стево ежедневно тратит около шести часов на управление своими страницами в Facebook. Он действует в рамках нечетких процессов модерации и принятия решений в Facebook, что может повлиять на его доходы. На момент нашего разговора одна из его страниц «Любители Бога» подвергалась ограничениям и не приносила ему дохода. Проблема была неясна, но она не была связана с фейковыми изображениями. Стево управляет другими страницами с более чем 100 000 подписчиков, которые используют изображения, созданные искусственным интеллектом. Facebook не раскрывает методологию расчета бонусов, и программа доступна только авторам в определенных странах (например, в США, Великобритании и Индии), что может объяснить, почему Стево во время нашего интервью часто утверждал, что он британский студент по кибербезопасности по имени Джейкоб. .
За всем этим очевидным контентом, созданным искусственным интеллектом, обычно работает человек — кто-то вроде Стивена (или иногда Джейкоба). Именно этот человек загружает похожие произведения, например, несколько романов о викингах с обложками в стиле искусственного интеллекта, все под названием «Гнев северян: захватывающая история викингов о мести и чести». Это название было опубликовано под разными именами авторов, таких как Сула Урбант, Сула Урбанц и Сула Урбанр. Эти люди собираются в онлайн-сообществах, таких как доски объявлений, чат-приложения и социальные сети, чтобы обмениваться методами. На Facebook группа под названием «Twitter Academy — Make Money on X», насчитывающая более 130 000 вьетнамских участников, обсуждает стратегии, позволяющие поручить ChatGPT создавать X-темы: «Вы влиятельный человек в Твиттере с большим количеством подписчиков, известный своим юмористическим тоном и творческим стилем письма. Вы не обращаетесь к себе и не объясняете, что делаете.
В Интернете также есть сотни тысяч видеороликов с подробными инструкциями, подобными тем, которые дал мне Стивен. Джейсон Кеблер, соучредитель 404 Media, независимого коллектива технических новостей, который выступает в качестве рекордсмена в мире помоев, просмотрел на YouTube десятки семинаров по помоям на хинди, многие из которых предлагали примеры подсказок: «Американский солдат ветеран держит картонную табличку с надписью «сегодня мой день рождения, пожалуйста, поставьте лайк» раненому в бою ветерану войны с американским флагом», «Старая американка лепит лесного льва из цветной капусты, а ее соседи смотрят на это. держите это подробно».
Проще говоря, люди, организующие такие семинары, используя стратегию, аналогичную продаже лопат во время золотой лихорадки, обычно зарабатывают больше, чем те, кто сами участвуют в семинарах. Они предлагают планы уроков, членство в частных чатах в Discord и Telegram и даже помогают международным участникам создавать учетные записи в США. Если мы сравним помоев с производственным сектором, то этих гуру, ваучеров и производителей инструментов можно рассматривать как представителей сектора услуг этой гипотетической экономики.
Эта экосистема не нова. Влиятельные люди десятилетиями пропагандировали платформозависимые схемы «интернет-маркетинга». Что изменилось, так это уровень работы и инвестиций. В последнее время предприниматели стали обычным делом передавать фактическое производство контента на аутсорсинг: «У меня есть два человека на Филиппинах, которые публикуют сообщения для меня», — рассказал один американский оператор страницы в Facebook The New York Times Magazine в 2016 году. Но когда у вас есть автоматизированная машина для пост-творения, кому нужны два человека на Филиппинах? Если уж на то пошло, учитывая сложность ИИ, зачем филиппинцам нужен американец?
Трудно точно определить количество сфабрикованного контента или «отбросов», созданных с момента широкого использования приложений генеративного искусственного интеллекта из-за отсутствия точных методов. Однако Гийом Кабанак, профессор информатики Университета Тулузы III имени Поля Сабатье, уже несколько лет работает над выявлением случаев мошенничества, плагиата и текста, созданного ИИ, в крупных научных журналах. Один из подходов, который он использует, — сосредоточиться на том, что он называет «дымящимися пушками» — отдельными фразами, которые ясно указывают на использование генератора текста искусственного интеллекта, такого как ChatGPT. Например, такая фраза, как «регенерировать ответ», которая появляется в конце некоторых ответов ChatGPT, является одним из таких явных доказательств. По словам Кабанака, эти фразы часто остаются неудаленными людьми, которые беззаботно копируют и вставляют текст. Другие распространенные фразы, используемые чат-ботами, включают «как языковую модель искусственного интеллекта», «на момент прекращения моих знаний» и «Я не могу выполнить этот запрос».
Исследователь Кабанак обнаружил около сотни научных статей, написанных с помощью ИИ, назвав их лишь началом гораздо более серьезной проблемы. В недавнем исследовании библиотекаря Эндрю Грея использовались такие термины, как «похвальный», «сложный» и «дотошный», которые слишком часто встречаются в тексте, генерируемом такими моделями, как ChatGPT. Эти слова использовались для оценки того, что около 60 000 научных статей, написанных в 2023 году, могли быть, по крайней мере частично, написаны системами искусственного интеллекта.
Вы можете провести свои собственные версии этих экспериментов дома. Поиск «на уровне моих знаний» или «как языковая модель искусственного интеллекта» в Google Книгах выдает сотни созданных искусственным интеллектом «книг» с такими названиями, как 100 ведущих актеров Голливуда и Резюме, если Женщина во мне: Путеводитель по мемуарам Бритни Спирс. На Amazon в результате быстрого поиска был найден список некоторого (предположительно настоящего) нижнего белья с описанием «Насколько мне известно, в начале 2023 года будут прекращены специальные варианты покупки». Женские стильные сексуальные повседневные трусики с принтом в честь Дня независимости были бы моими возможностями, поскольку я не могу просматривать или получать доступ к актуальным данным из Интернета, включая текущие запасы от или частных продавцов ».
Twitter, известный как X Илона Маска, может быть лучшей платформой для такого поиска благодаря своей относительно мягкой политике модерации. В январе Крис Мохни, писатель и редактор, заметил твит, который, казалось, описывал изображение без прикрепленного изображения: «На фотографии запечатлена пара, обменивающаяся клятвами на закате. Чувства, которые она вызывает, — это любовь, счастье и воспоминания о особенный день, полный обещаний». Сотни проверенных аккаунтов похвалили несуществующее изображение: «Эта фотография излучает чистую любовь и радость, поистине волшебный момент!», «Это фото прекрасно воплощает красоту и волшебство настоящей любви», «Какой прекрасный момент запечатлен на время, переполненное любовью и радостью.
Кабанак утверждает, что модели юридического языка (LLM) могут быть исключительным и высокоэффективным ресурсом для ученых при правильном использовании. Однако некоторые исследователи, особенно те, кто в основном не говорит по-английски, могут полагаться на программы искусственного интеллекта, такие как ChatGPT, для помощи в переводе и редактировании. К сожалению, чрезмерная зависимость от этих инструментов может привести к снижению общего качества научных публикаций. Эта проблема, даже если она кажется незначительной, может оказать снежный ком на все научное сообщество, поскольку отозванные статьи вызывают сомнения в отношении других исследований, в которых они ссылаются. По его словам: «Ошибка распространяется, не так ли? Это как вирус.
По мнению Кабанака, статьи, созданные с помощью ИИ, часто используются учеными для дополнения своих резюме дополнительными публикациями и цитатами. Это можно резюмировать так: «Вы приобретаете статью по интересующей вас теме вместе с 500 цитатами. Затем вы представляете их своему академическому учреждению, заявляя: «Я исключительно талантлив и заслуживаю повышения до звания профессора». ‘ По сути, значение заключается не в качестве или содержании произведения, а скорее в его существовании — или, точнее, в его количественных аспектах.
Основное применение генеративных приложений искусственного интеллекта, обнаруженное на данный момент, — это создание контента, который занимает пространство и может быть измерен количественно. При изучении огромных объемов онлайн-контента ИИ выглядит не как устрашающий апокалиптический бог-машина, возвещающий новую технологическую эпоху, а скорее как вершина эры смартфонов — идеальный инструмент интернет-маркетинга, тщательно созданный для удовлетворения мимолетных потребностей. , желания наименьшего общего знаменателя, подпитывающие бесконечную прокрутку.
Приятно представить, что, выключив телефон и компьютер, можно спастись от этих неприятных творений. Однако кажется, что мусор часто находит способ просочиться наружу. Например, в последнем сезоне «Настоящего детектива» в одной из сцен был заметен созданный искусственным интеллектом постер хэви-метала. Шоураннер заявил, что плакат действительно был создан искусственным интеллектом в рамках сюжетной линии. Аналогичным образом, в метро в рекламе сайта подержанной мебели Kaiyo представлены изображения пешеходов, кажущихся неестественно плывущими, и текст, написанный характерными глифами, которые часто встречаются в текстовых попытках, генерируемых искусственным интеллектом.
Аутсорсинг проектных работ приложениям генеративного искусственного интеллекта может быть эффективной мерой сокращения затрат и повышения производительности для некоторых предприятий, но на практике он просто разгружает работу в других местах. Стоимость помоев для библиотек серьезна, сказал Салливан, «не только стоимость книг», но и стоимость рабочей силы: каталогизаторам требуется больше времени для выполнения своей работы, когда они преодолевают «излияние бесполезной продукции». Людям-художникам, писателям, журналистам, музыкантам и даже тиктокерам тоже предстоит больше работы, конкурируя не только с другими людьми, но и с сносными продуктами автоматизированных систем.
С моей точки зрения как наблюдателя, кажется, что нас, зрителей, ждут впереди новые задачи. Будущее, сформированное за последние два года, похоже, такое, в котором мы все возьмем на себя роль кураторов, просеивая хаос в поисках намека на ясность, во многом подобно тому, как Нил Кларк ориентируется в шуме. Даже контент, который удается дойти до нас, представляет собой проблему; сырой, неотшлифованный и поэтому требует больше усилий для чтения, просмотра, расшифровки и понимания.
Похоже, что мы тоже в некотором смысле вносим свой вклад в эту ситуацию. Наряду с помоями, влиятельными лицами и платформами, мы — пользователи — играем значительную роль в функционировании отстойной экономики. Всякий раз, когда мы случайно просматриваем Facebook, TikTok или Twitter на наших телефонах, позволяем музыке автоматически воспроизводиться на Spotify, покупаем бюджетные книги рецептов на Amazon, мы все подпитываем спрос.
Около полутора десятилетий назад журнал Wired объявил о «достаточно хорошей революции» в доступных технологиях: «Недорогие, быстрые и несложные инструменты стали повсеместными… Мы стали предпочитать адаптируемость качеству, удобство сложности, быстроту и грубый, а не медленный и изысканный». Генеративный ИИ подпадает под эту традицию. Его способность генерировать удовлетворительные тексты и изображения представляет собой выдающийся прогресс в области искусственного интеллекта, однако эти результаты просто адекватны, «достаточно хороши» для быстрой прокрутки на смартфонах. Термин «отстой» лучше всего описывает его продукцию, потому что, хотя он может показаться неприятным, мы все равно его потребляем. Это простой в использовании вариант прямо перед нами.
Смотрите также
- ‘1000 фунтов. Звезда сериала «Сестры» Эми Слейтон покинула зоопарк на носилках перед арестом после предполагаемого укуса верблюда.
- МТС акции прогноз. Цена MTSS
- Этель Кейн полностью взорвала социальные сети из-за недавнего политического заявления
- ПИК акции прогноз. Цена PIKK
- Роснефть акции прогноз. Цена ROSN
- Эксперты предсказывают следующий шаг сиба-ину: цена SHIB скоро достигнет $0,00016
- Цена Hamster Kombat против X Empire: куда инвестировать в октябре?
- Ожидается ли рост доллара к тайскому бату?
- ВК акции прогноз. Цена VKCO
- Россия отберет средства у опального бывшего магната – СМИ
2024-09-25 12:14